If you just want the R code to delete some tweets based on age and likes, here it is (noting that it is based on Chris Albon’s Python script). In this post, I go over a bit of code about what I thought was an interesting problem: given a list of tweets, how can we identify and group threads?
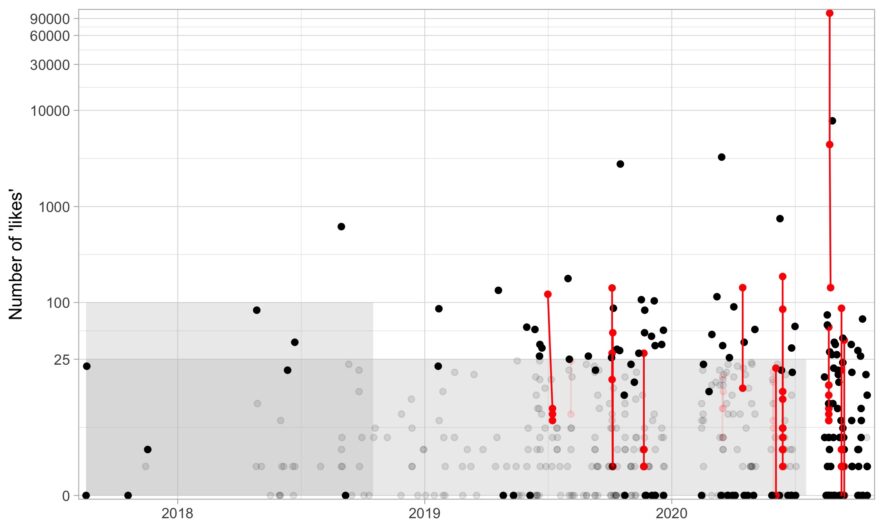
Below, I plot all my tweets over time (x-axis) by the number of “likes” (y-axis) and I highlight in red tweets that are threaded together. Ignore the boxes for now.

Pulling the data using rtweet, you end up with a dataframe that looks something like this (only with many many more rows and columns):
> before_df %>% select(status_id, created_at, screen_name, text, reply_to_status_id) # A tibble: 510 x 5 status_id created_at screen_name text reply_to_status… <chr> <dttm> <chr> <chr> <chr> 1 13167994911… 2020-10-15 17:53:58 mathewkiang "@JosephPalamar Haha — the on… 131679883199713… 2 13167817880… 2020-10-15 16:43:37 mathewkiang "@khayeswilson Ah \"self-liki… 131678029839121… 3 13167812579… 2020-10-15 16:41:31 mathewkiang "@khayeswilson AH! This is pe… 131678029839121… 4 13167755278… 2020-10-15 16:18:44 mathewkiang "I've been coding up a script… NA 5 13165350914… 2020-10-15 00:23:20 mathewkiang "https://t.co/7PtlUKWTeU http… NA 6 13161332751… 2020-10-13 21:46:40 mathewkiang "Data: Full-time academic job… NA 7 13144052234… 2020-10-09 03:20:00 mathewkiang "@simonw Thanks for the info!… 131439639207741… 8 13143912914… 2020-10-09 02:24:38 mathewkiang "@simonw Does this include da… 131439055526721… 9 13142896495… 2020-10-08 19:40:45 mathewkiang "Me: This paper has been out … NA 10 13136475049… 2020-10-07 01:09:06 mathewkiang "@Doc_Courtney If by “passing… 131364337679803… # … with 500 more rows
To select the tweets you want to delete, it is straight-forward to make a rule like: (1) delete all tweets created more than two years ago with fewer than 100 likes (left-most grey box in the plot) or (2) delete all tweets created more than 90 days ago with fewer than 25 likes (bottom grey box in the plot). You could even create a function where the number of likes must be exponentially higher over time. And obviously, you can create a list of tweets (status_ids) that you want to keep.
However, this assumes all tweets are independent. Things get a bit more complicated if you want to treat sets of tweets with the score of any single tweet in the set. If, for example, you string together a twitter thread, you may want to delete or save the entire thread based only on the first tweet since deleting the “unliked” tweets will break up the thread. Twitter doesn’t provide a column that links threads together through a unified ID.
After chatting with Malcolm Barrett about it for a bit, I realized this is a fairly simple network problem. If you imagine the data frame above, where every row is a tweet, as an edge list between vertex status_id and reply_to_status_id, then you can remove all isolates to get trees of threads (most would just be chains). The key code is here but to sketch out the broad points:
- Take
before_dfand (a) filter out isolates (e.g., non-threaded tweets) by making sure each tweet is referred to by another tweet or refers to another tweet within the data frame and (b) removing comments to other people by removing tweets that start with “@”. Because it’s an edge list, we will rename the columns to “from” and “to” and if there is no terminating vertex (i.e., it’s the first tweet in a thread), we will create a self-loop.before_df %>% filter(status_id %in% reply_to_status_id | reply_to_status_id %in% status_id, substr(text, 1, 1) != "@") %>% select(from = status_id, to = reply_to_status_id) %>% mutate(to = ifelse(is.na(to), from, to)) - Now just convert this edge list into a graph and extract all the components using
igraphthread_assignments <- thread_df %>% graph_from_data_frame(directed = TRUE) %>% components() - Now you have a mapping of every threaded tweet ID to a component ID. Below, I just take this mapping and then create a new component ID that is the same as the starting tweet of the thread.
id_mapping <- thread_df %>% select(status_id = from) %>% left_join(tibble( status_id = names(thread_assignments$membership), membership = thread_assignments$membership )) %>% group_by(membership) %>% mutate(new_status_id = min(status_id)) %>% ungroup()
That’s it! With this mapping, you can left_join() the original data frame and perform manipulations on the thread as a group of tweets rather than each tweet individually. Anyways, check out the gist to see how I deleted the tweets and implemented this. I just thought it was a nice, clean application of an introductory-level network concept to an applied data cleaning problem.
After deleting old and boring tweets and keeping tweets I liked (taking into account groups), I’m left with the black points above. The grey points were tweets that I ended up deleting.
(Disclaimer: There’s almost certainly a better way to do this — I just don’t know it.)